存储过程是一个SQL语句集合,当主动去调用存储过程时,其中内部的SQL语句会按照逻辑执行
存储过程和函数有点类似,在函数体里不能写SQL语句,而存储过程可以,且存储过程没有返回值这一概念(下面提到的返回值只是为了方便说明)
存储过程和触发器一样需要修改SQL语句终止符
1. 不带参数的存储过程
# 基本语法
delimiter //
create procedure 存储过程名称 ()
begin
SQL语句;
SQL语句;
end //
delimiter ;
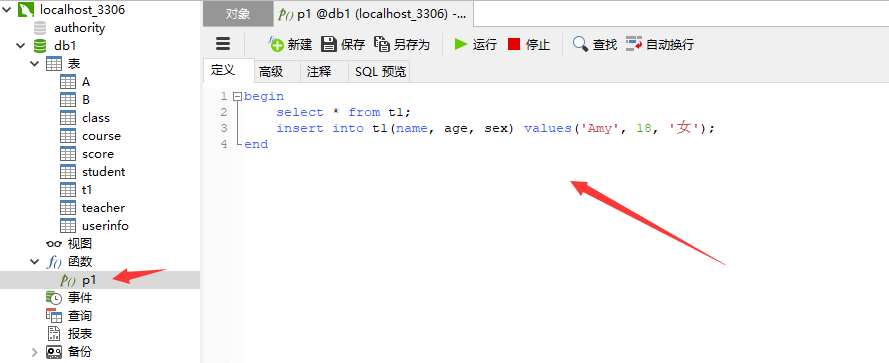
# 创建存储过程
delimiter //
create procedure p1 ()
begin
select * from t1;
insert into t1(name, age, sex) values('Amy', 18, '女');
end //
delimiter ;
# 调用存储过程
# call 存储过程名称()
call p1()
2. 带参数的存储过程
- 对于存储过程,可以接收参数,其参数有三类:
- in -> 仅用于接收传入的参数且不进行返回操作时使用
- out -> 仅用于返回值使用,就算外部传入了值 out 也接收不到,且 out 只会接收一个变量名也必须要接受一个变量名,而这个变量名就是存储过程外部的变量名,只要将存储过程中的值赋值给这个变量名,存储过程外部就可以通过这个变量名获取到存储变量内部的值 -> 一般用于标识存储过程的执行结果
- inputout -> 即可以接受传入的参数也可以进行返回值操作
# 基本语法
delimiter //
create procedure 存储过程名称 (
in 参数名称 SQL的数据类型,
out 参数名称 SQL的数据类型,
inputout 参数名称 SQL的数据类型,
)
begin
SQL语句;
SQL语句;
end //
delimiter ;
- in -> 仅用于接收传入的参数且不进行返回操作时使用
# in 的用法
# 创建存储过程
delimiter //
create procedure p1 (
in d1 int -- 定义所接收到参数的SQL数据类型
)
begin
select * from t1 where id < d1;
end //
delimiter ;
# 调用存储过程
call p1(5)
- out -> 仅用于返回值使用,无法接收传入的参数,只会接收一个变量名也必须要接受一个变量名,而这个变量名就是存储过程外部的变量名,只要将存储过程中的值赋值给这个变量名,存储过程外部就可以通过这个变量名获取到存储变量内部的值
# out 的用法
# 创建存储过程
delimiter //
create procedure p1 (
out d1 int -- 定义返回值的SQL数据类型
)
begin
select d1; -- 就算外部有值传入out也无法接受到,只会接收一个全局变量
set d1 = 123; -- 对接收到的全局进行赋值
end //
delimiter ;
# 调用存储过程
set @v1 = 456; -- 定义session级别的变量 -> 全局变量
call p1(@v1); -- out 必须接收一个session级别的变量
select @v1; -- 查询存储过程的返回值


- inout -> 即可以接受传入的参数也可以进行返回值操作
# inout 的使用
# 创建存储过程
delimiter //
create procedure p1 (
inout d1 int -- 定义所接收到参数的SQL数据类型和返回值的SQL数据类型
)
begin
select d1; -- 查询外部传入的值,inout是可以接受到外部传入的值和全局变量
set d1 = 123; -- 对接收到的全局变量进行赋值
end //
delimiter ;
# 调用存储过程
set @v1 = 456; -- 定义session级别的变量 -> 全局变量
call p1(@v1); -- inout 必须接收一个session级别的变量
select @v1; -- 查询存储过程的返回值


3. 事务
# 通过存储过程实现事务
delimiter \\
create procedure p1(
out p_return_code tinyint
)
begin
declare exit handler for sqlexception -- 如果出现异常就会执行下方代码块的异常代码
begin
-- 执行异常代码
set p_return_code = 1;
rollback; -- 回滚,回到初始状态
end;
start transaction; -- 开始事务
delete from t1; -- 执行SQL语句
commit; -- 进行提交
-- 成功,没有出现异常
set p_return_code = 2;
end\\
delimiter ;
# 调用事务 -> 返回 2 则没有出现异常,返回 1 则出现异常,通过返回值进行判断处理其他事情
set @v1 = null;
call p1(@v1);
select @v1;
4. 游标
- 相当于 for 循环
- 性能不高
- 游标循环是不会自己结束的,需要进行判断手动结束循环
- 使用场景: 对表中每一条数据进行单独的操作的时候才会使用到游标(一般是DBA才会使用的,因为DBA不会写Python代码使用循环,只能通过游标实现循环)
# 以Python的形式写SQL语句 -> 方便理解下方代码
for row_id, row_num in my_cursor:
insert into B(num) values(row_id + row_num)
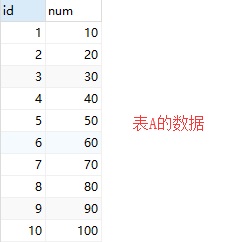
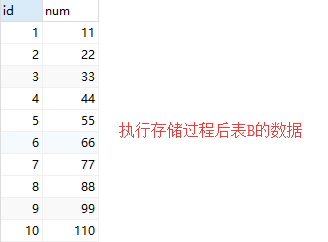
# 通过存储过程实现数据的循环
# 循环表A的数据然后对表A的 id 和 num 进行相加然后翻进表B中
delimiter //
create procedure p1()
begin
declare row_id int; -- 定义变量1
declare row_num varchar(50); -- 定义变量2
declare done int default false; -- 定义 done 变量,默认值为 false,用于判断循环是否可以结束了
declare temp int;
declare my_cursor cursor for select id, num from A; -- 声明一个名为 my_cursor 的游标,cursor for 是关键字,从A表中获取数据放到游标中然后进行循环
declare continue handler for not found set done = true; -- 检测游标里是否还有数据,如果没有变量 done 变成 true
open my_cursor; -- 打开游标
xxoo: loop -- 开始循环
fetch my_cursor into row_id, row_num; -- 从游标中获取一行数据然后赋值给 row_id, row_num
if done then -- 判断 done 是否为true,如果为 true 则代表游标中已经没有数据可以结束循环了
leave xxoo; -- 跳出循环
end if;
set temp = row_id + row_num;
insert into B(num) values(temp);
end loop xxoo;
close my_cursor; -- 关闭游标
end //
delimiter ;
# 调用存储过程
call p1();

5. 动态执行 Mysql 语句
- 通过动态执行 MySQL 语句,在数据库级别上实现防止SQL注入
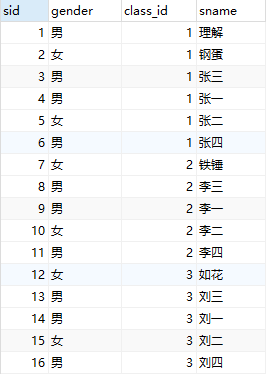
- student表的所有数据
# 定义存储过程,动态执行 Mysql 语句,在数据库级别上实现防止SQL注入
delimiter \\
create procedure p1 (
in sid int
)
begin
set @xo = sid; -- 声明session级别的变量
prepare xxx from 'select * from student where sid < ?'; -- 定义SQL语句 -> ? 代表占位符
execute xxx using @xo; -- 格式化SQL语句,将SQL语句的 ? 占位符替换成 @xo 变量,且这个变量必须是session级别的变量,如果不是就会报错
deallocate prepare xxx; -- 执行格式化完成后的SQL语句
end\\
delimiter ;
# 调用存储过程
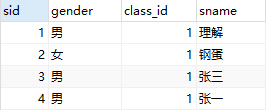
call p1(5);
← 子查询 对查询到的数据进行条件判断 →