索引就相当于一个目录可以快速查找到想要的数据
索引的作用: 约束、加速查找
索引的种类
- hash索引: 以表的形式存储索引 -> 单值查询非常的快,但是范围查询会很慢
- btree索引: 使用红黑树结构进行索引的存储 -> 常用
在创建索引的时候会创建额外的文件保存索引的特殊数据结构,这样就会导致查询数据会很快,但是在进行数据的增删改就会比较慢(因为在进行数据的增删改的时候它还要更新索引文件(额外文件)的特殊数据结构)
数据表:数据表就是数据库里的表,数据表也叫物理表
索引表:在创建索引时所创建的额外文件,而该文件保存的是索引的特殊数据结构
在索引表中查询数据会比在数据表中查询数据要快
创建表后且表里面有了数据再执行添加索引的SQL语句时,执行时间会比较长
通过索引查询数据的执行循序: 先去索引文件里面找,再去数据表里面找
索引散列值(重复的数据比较多),不适合使用索引 -> 例如: 性别,只有两个值可选,且在表中的性别列的数据重复性比较大
在不使用索引的前提查找数据,会将数据库的数据从头到尾查找一遍
1. 表结构和数据
- 表的结构
create table userinfo (
id int(11) not null auto_increment,
username varchar(10) not null,
age int(11) not null,
email varchar(50) not null,
address varchar(5) not null,
primary key (id)
) engine=innodb default charset=utf8;
- 使用 pymysql 添加一百万条数据
import pymysql
import random
conn = pymysql.connect(host='localhost', user='root', password='', database='db1', charset='utf8')
cursor = conn.cursor()
address_lis = ['东莞', '广州', '深圳', '茂名', '化州', '潮州', '汕尾', '汕头', '河源', '桂林']
for i in range(1, 1000001):
sql = 'insert into userinfo(username,age,email,address) values(%s,%s,%s,%s)'
result = cursor.execute(sql, ['用户%s' % i, random.randint(0, 100), '用户%s@qq.com' % i, address_lis[random.randint(0, 9)]])
print(result, i)
cursor.close()
conn.close()
2. 普通索引(单列普通索引) -> 加速查找
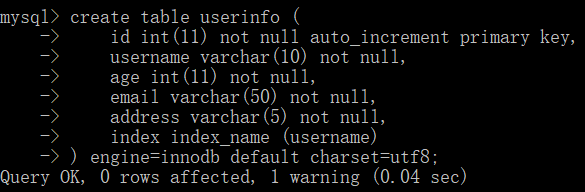
- 创建表时添加普通索引
# index 索引名 (字段名)
create table userinfo (
id int(11) not null auto_increment primary key,
username varchar(10) not null,
age int(11) not null,
email varchar(50) not null,
address varchar(5) not null,
index index_name (username) -- 将 username 字段设置为索引
) engine=innodb default charset=utf8;
- 创建表后添加普通索引
# create index 索引名 on 表名(字段名);
create index index_name on userinfo(username);

- 删除普通索引
# drop index 索引名 on 表名;
drop index index_name on userinfo;

- 查看该表的所有索引
# show index from 表名;
show index from userinfo;

3. 联合普通索引 -> 加速查找
- 多列组成一个索引
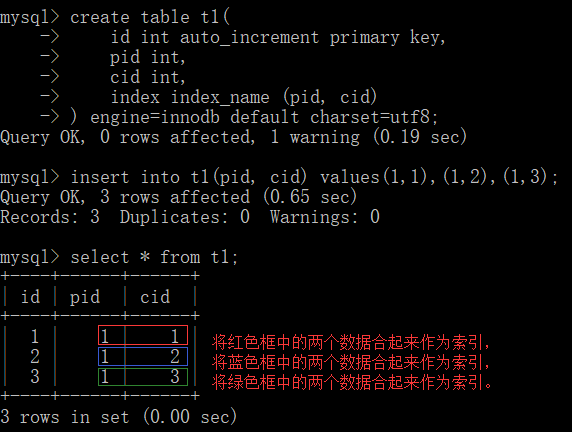
- 创建表时添加普通联合索引
# index 索引名称 (字段名, 字段名, ……)
create table t1(
id int auto_increment primary key,
pid int,
cid int,
index index_name (pid, cid)
) engine=innodb default charset=utf8;
- 创建表后添加普通联合索引
# create index 索引名 on 表名(字段名, 字段名, ……);
create index index_name on t1(pid, cid);

4. 唯一索引(单列唯一索引) -> 加速查找 + 数据不能重复
- 唯一索引: 不允许数据重复
- 唯一索引和主键的区别: 主键不能为空,而唯一索引能允许有一个为空
- 创建表时添加唯一索引
# 写法一
# unique 唯一索引名 (字段名);
create table t1(
id int auto_increment primary key,
pid int,
unique uq (pid)
) engine=innodb default charset=utf8;
# 写法二
# 直接在字段后面加上 unique
create table t1(
id int auto_increment primary key,
pid int unique
) engine=innodb default charset=utf8;

- 创建表后添加唯一索引
# create unique index 唯一索引名 on 表名(字段名);
create unique index uq on t1(pid);

- 删除普通索引
# drop index 唯一索引名 on 表名;
drop index uq on t1;

5.联合唯一索引 -> 加速查找 + 数据不能重复
- 多列组成一个索引
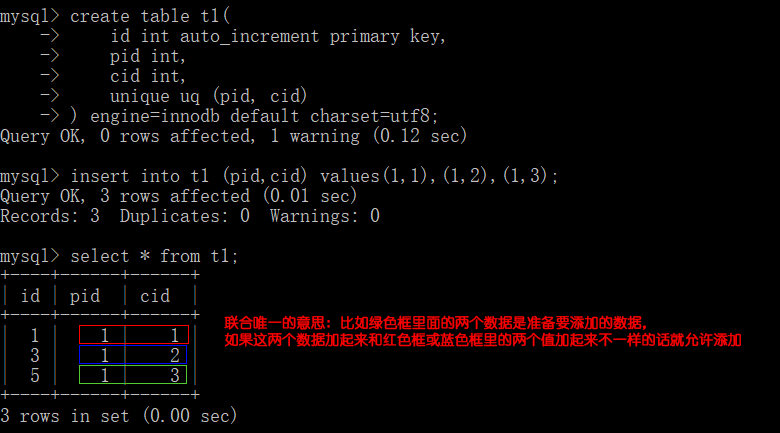
- 创建表时添加联合唯一索引
# unique 唯一索引名 (字段名1, 字段名2, ……);
create table t1(
id int auto_increment primary key,
pid int,
cid int,
unique uq (pid, cid)
) engine=innodb default charset=utf8;
- 创建表后添加联合唯一索引
# create unique index 唯一索引名 on 表名(字段名, 字段名, ……);
create unique index uq on t1(pid, cid);

6.主键索引(其实就是主键 + 自增) -> 加速查找 + 数据不能重复(不能为空)
- 主键索引: 不允许数据重复
- 主键和唯一索引的区别: 主键不能为空,而唯一索引能允许有一个为空
- 创建表时添加主键索引
# 写法一
create table userinfo (
id int(11) not null auto_increment primary key,
username varchar(10) not null,
age int(11) not null,
email varchar(50) not null,
address varchar(5) not null
) engine=innodb default charset=utf8;
# 写法二
create table userinfo (
id int(11) not null auto_increment,
username varchar(10) not null,
age int(11) not null,
email varchar(50) not null,
address varchar(5) not null,
primary key (id)
) engine=innodb default charset=utf8;
- 创建表后添加组件索引
# alter table 表名 add primary key(字段名);
alter table userinfo add primary key(id);
- 删除主键索引
# alter table 表名 drop primary key;
alter table userinfo drop primary key;
7.局部索引
- create index/unique index 索引名称 on t1(字段名(length)) -> 将字符串类型的前 length 个字符作为索引
# 将 username 数据中的前 2 个字符作为索引
create index index_name on userinfo(username(2));
- 创建索引时如果是 blob 和 text 类型的必须指定 length 不然就会报错
# 如果 address 是 text 或 blob 类型的, 那么创建索引的时候一定要指定 length
create index index_name on userinfo(address(20));
7.使用索引和不使用索引的查询速度对比
# 有索引 -> username 设置为索引的前提下
select * from userinfo where username='用户999999';
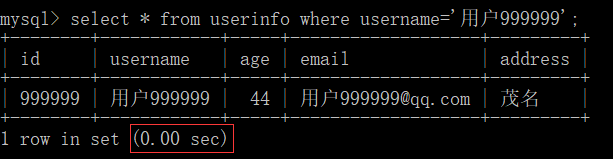
# 没有索引
select * from userinfo where username='用户999999';
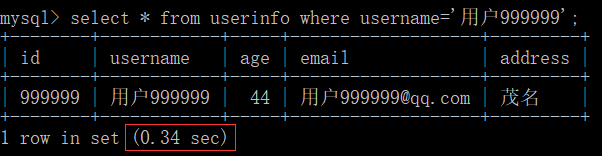
8.覆盖索引 和 索引合并
- 覆盖索引和索引合并是名词,不是真正意义上的的索引,只有在特殊的情况下使用索引就会叫这两个名字
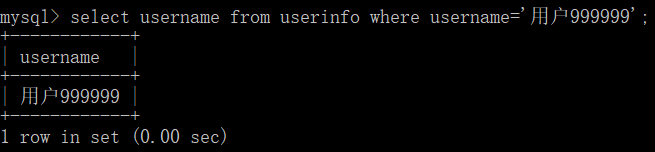
- 覆盖索引 -> 在索引文件中直接获取数据
# 在 username 作为索引的前提下,直接从索引文件中获取 username 这一列数据(因为在创建索引的时候已经把username这一列数据保存到索引文件中了,所以可以直接从索引文件中获取)
select username from userinfo where username='用户999999';

- 索引合并 -> 把多个单列索引合并在一起使用 -> 索引合并的速度要比联合索引的要慢 -> 索引合并和下方的联合索引注意事项用法有点类似
# 在 username 、email、address作为单列索引的前提下
select * from userinfo where username='用户999999' and email='用户999999@qq.com' and address='茂名';


9.联合普通/唯一索引的注意事项
- 使用联合索引代替多个单列索引(同时使用多个单列索引进行条件查询 -> 简称: 索引合并),因为联合索引的速度比较快
- 这里的注意事项和索引合并的用法有一点类似,不同之处在于联合索引遵循最左前缀规则,而索引合并可以随便搭配以设置了索引的字段名,但是联合索引的速要比索引合并的要快
- 联合索引会遵循一个规则: 最左前缀 -> 意思就是只有和联合索引中设置的第一个字段名搭配着使用或单独使用联合索引中设置的第一个字段名才会使用到索引(有加速)
# 如果联合索引为:
create index index_name on userinfo(username, email, address);
# 如果查询的时候 username 在前面就会使用到索引,有加速
select username,email from userinfo where username='用户999999' and email='用户999999@qq.com';

# 如果查询的时候只有一个 username 那么也会使用到索引,有加速
select username,email from userinfo where username='用户999999';
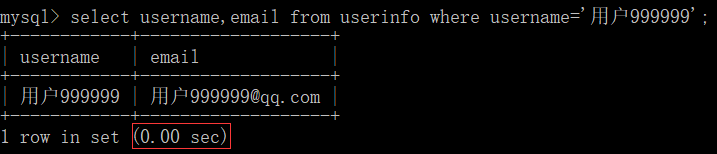
# 如果查询的时候 username 不在条件中是不会使用到索引的就算 email 和 address 在联合索引中,没有加速
select username, age from userinfo where username='用户1000' and age=74;

# 如果查询的时候只有一个除了 username 以外的字段名那么也不会使用到索引就算 email 或 address 在联合索引中,没有加速
select username,email from userinfo where email='用户999999@qq.com';
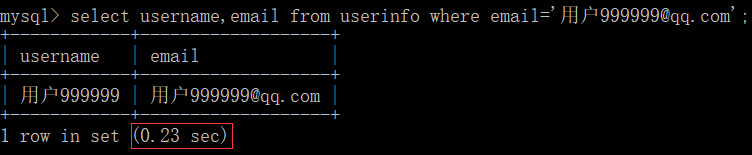
10.正确使用索引
- 数据库表中添加索引后确实会让查询速度变快,但前提必须是正确的使用索引来查询,如果以错误的方式使用,即使建立了索引也会不奏效
- 即使建立索引,索引也不会生效的示范:
- like '%xxx'
# like '%xxx' -> 就算 username 已经设置为索引,但是使用 like 进行模糊查询也是会没有使用上索引(没有加速)
select * from userinfo where email like '%用户1000000@qq.com';
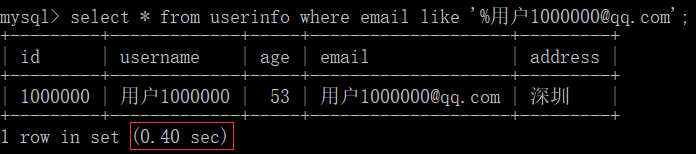
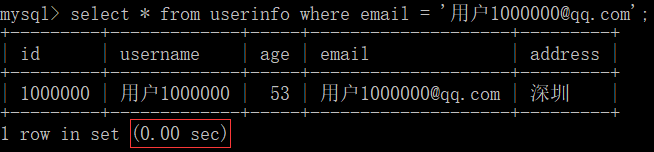
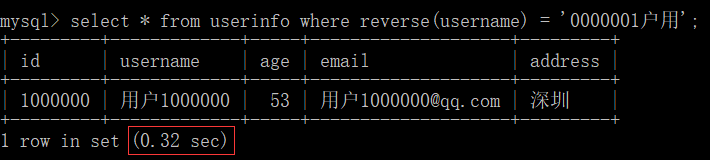
- 函数 -> 使用某些函数也会导致索引不会生效(不加速)-> 例如: reverse()
select * from userinfo where reverse(username) = '0000001户用';
- or -> 一个字段设置了索引,另一个字段没有设置索引,当使用 or 进行条件查询的时候,索引就会不生效 -> 如果字段A设置了索引,字段B没有设置索引,当字段A和字段B使用 or 进行条件查询的时候也会导致索引不会生效(不加速)
# username 设置了索引, email 没有设置索引
select * from userinfo where username='用户999999' or email='用户999999@qq.com';

# 特殊情况: 索引字段名 = xxx or 没有设置索引字段名 = 'xxx' and 索引字段名 = xxx -> 索引是会生效的,因为它会忽略掉没有设置索引字段名 or 的那一部分
# username 设置了索引, email 没有设置索引, address 设置了索引
select * from userinfo where username='用户999999' or email='用户999999@qq.com' and address='茂名';

- 类型不一致
# email 为索引的前提下,如果 email 的数据类型是字符串,但是在进行条件查询的时候传入的是数字类型,那么也会导致索引不会生效(不加速),因为在查询的时候要先将传入的数字类型的数据转换为字符串类型的数据然后再进行查询
select * from userinfo where email=123;


- !=
# email 为索引的前提下,如果 email 使用了 != 进行条件查询也会导致索引失效(不加速)
select * from userinfo where email != '用户1000@qq.com';
# 特殊情况: id 为主键的前提下,如果 id 使用了 != 进行条件的查询,主键索引是会生效的(加速)
select * from userinfo where id != 1000;
- > < >= <=
# 如果索引是字符串类型的就会导致索引不会生效(不加速),因为在查询的时候要先将传入的字符串类型的数据转换为数字类型的数据然后再进行比较
select * from userinfo where age > '30';
# 特别情况:主键或索引是数字类型,则索引还是会生效(加速) -> id 为主键的前提下 或 age 为索引的前提下
select * from userinfo where id > 30;
select * from userinfo where age > 30;
- order by -> 排序
# 当根据索引字段进行排序的时候,选择的映射如果不是索引字段(查询数据的字段名不是索引的字段名),则会导致索引失效(不加速)
# 当 age 为索引的前提下
select email from userinfo order by age desc; -- 索引会失效(不加速)
select age from userinfo order by age desc; -- 索引不会失效(加速)
# 特殊情况: 如果对主键进行排序,主键索引还是会生效的(加速)
select * from userinfo order by id;
11.全文索引
- 每个字段都是索引