思维导图:
注:红色和黄色一定要记住
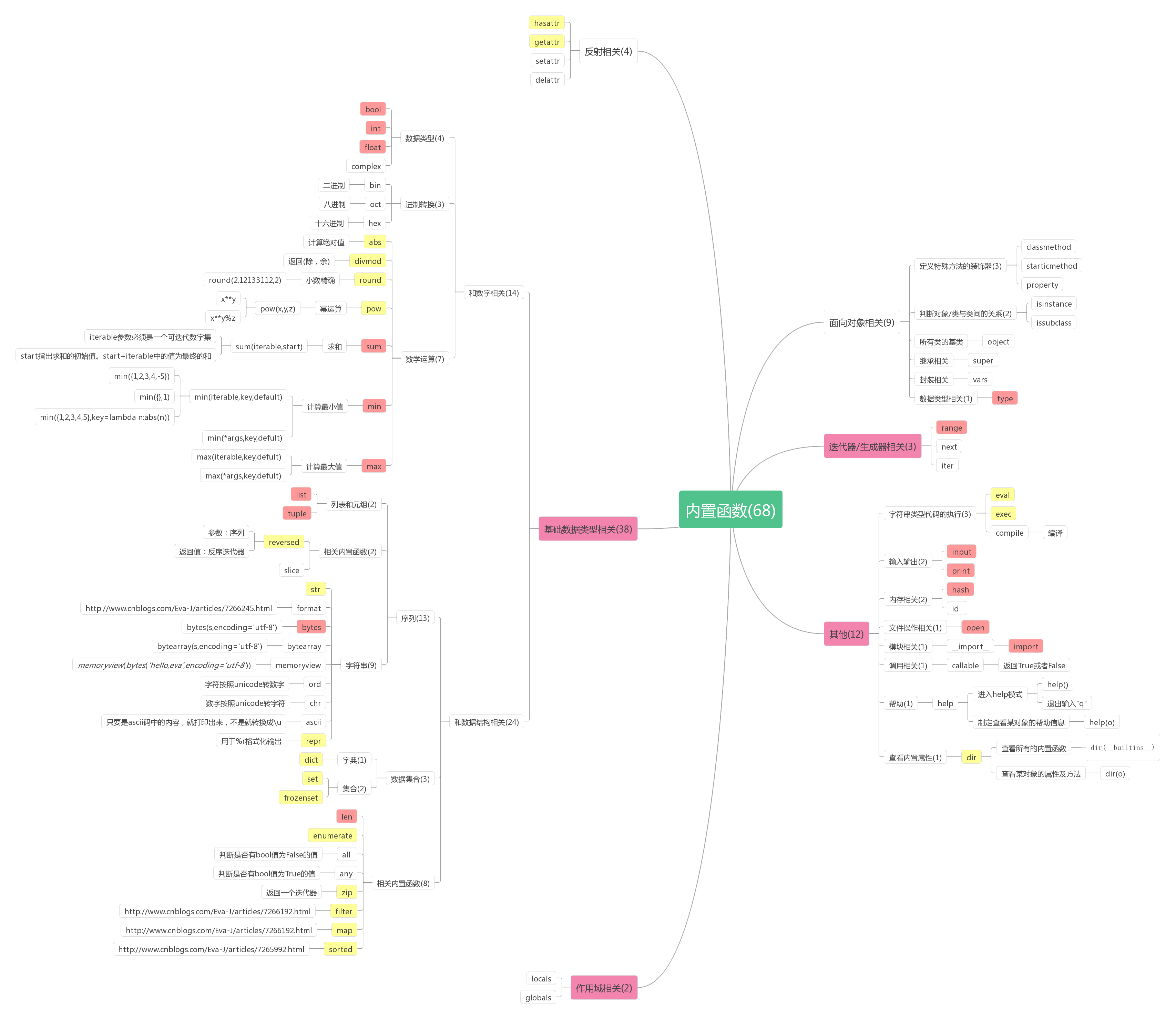
在该篇章中所写序列代表着 列表 元组 字典 集合
可以使用 函数名/匿名函数 的 内置函数:
- min() -> 最小值
- max() -> 最大值
- filter() -> 过滤器
- map() -> 通过函数的返回值组建新的序列
- sorted() -> 排序
1. 数据类型转换
- int()
- str 转 int
str_int = '10'
str_space_int = ' 12 '
int1 = int(str_int) # 10
int2 = int(str_space_int) # 12
- bool 转 int
bool_true = True
bool_false = False
int_true = int(bool_true) # 结果 1
int_false = int(bool_false) # 结果 0
- float() -> str 转 float
str_float = '2.1'
float = float(str_float)
- str() -> int 转 str
int = 10
str = str(int)
- bool() -> 任何类型 转 bool
airList = []
valuedList = [1]
zero = 0
str_null = ''
bool_ari_list = bool(airList) # 结果 False
bool_valued_list = bool(valuedList) # 结果 True
bool_zero = bool(zero) # 结果 False
bool_str_null = bool(str_null) # 结果 False
- list()
- tuple 转 list
aTuple = (1, 2 ,3, 4)
clist = list(aTuple) # 结果 [1, 2, 3, 4]
- 迭代器/生成器 转 list
def generator():
yield 1
yield 2
yield 3
g = generator()
g_lis = list(g) # [1, 2, 3]
- tuple() -> list 转 tuple
aList = [1, 2, 3, 4]
cTuple = tuple(aList) # 结果 (1, 2 ,3, 4)
2. 数字运算
- abs() -> 取绝对值
a1 = abs(5) # 5
a2 = abs(-5) # 5
- divmod(被除数,除数) -> 返回 商 和 余数
- 一般用作于分页,比如:一共有 8 条数据,每页分 3 条数据,那么 8÷3 得到的【商为2 + 1 (余数为2就是多出来的数据要另起一页存放该数据,所以才要 +1 如果余数为0就不需要 +)】就是总页数
- 求总页数的公式: 商 + 1 if 余数 else 商
b_r = divmod(7, 3) # (3, 1) 商 = 3 余数 = 1
# 随意写一个20行以上的文件
# 运行程序,先将内容读到内存中,用列表存储。
# 接收用户输入页码,每页5条,仅输出当页的内容
# 分页例子 写法一: 直接读取出来 节省内存
def page_content(num):
with open('file.txt', encoding='utf-8') as f:
l = f.readlines()
data_num = 5 # 每页显示多少条数据
page, mod = divmod(len(l), data_num)
page_num = page + 1 if mod else page # 总页数
if 0 < num <= page_num:
if num == page_num and mod != 0: # 如果是最后一页且这一页是由多余数据组成的
for i in range(mod):
# 计算方法一: 页数 * 每页显示多少条数据 - 每页显示多少条数据 = 该页开始循环的下标
print('计算方法一 ' + l[num * data_num - data_num + i].strip())
# 计算方法二: (页数 - 1) * 每页显示多少条数据 = 该页开始循环的下标
print('计算方法二 ' + l[(num - 1) * data_num + i])
else:
for i in range(data_num):
# 计算方法一: 页数 * 每页显示多少条数据 - 每页显示多少条数据 = 该页开始循环的下标
print('计算方法一 ' + l[num * data_num - data_num + i].strip())
# 计算方法二: (页数 - 1) * 每页显示多少条数据 = 该页开始循环的下标
print('计算方法二 ' + l[(num - 1) * data_num + i])
else:
print('输入的页数有误')
page_content(3)
# 随意写一个20行以上的文件
# 运行程序,先将内容读到内存中,用列表存储。
# 接收用户输入页码,每页5条,仅输出当页的内容
# 分页例子 写法二: 切片 在内存又存储了多一个列表
def page_content(num):
with open('file.txt', encoding='utf-8') as f:
l = f.readlines()
data_num = 5 # 每页显示多少条数据
page, mod = divmod(len(l), data_num)
page_num = page + 1 if mod else page # 总页数
if num > 0 and num <= page_num:
index_start = num * data_num - data_num # 获取切片的开始位置
index_end = index_start + 5 # 获取切片的结束位置
page_list = l[index_start:index_end]
for i in page_list:
print(i.strip())
else:
print('输入的页数有误')
page_content(5)
- round(float, num) 四舍五入保留 n 位小数
r_num = round(12.125456879, 2) # 12.13
- pow() -> 幂运算 = 运算符 **
power = pow(2, 3) # 8
# 等价于
power2 = 2 ** 3 # 8
# 幂运算后再取余
power = pow(2, 3, 2) # 0
- sum(可迭代对象) -> 求和
total =sum([1, 2, 3, 4]) # 10
- min(xxx, key=fn) -> 求最小值 -> key = 函数名/匿名函数 -> 如果有 key 那么就会通过 key 的函数返回值进行比较
s_num = min(-5, 1, 2, 3) # -5
s_num2 = min([-5, 1, 2, 3]) # -5
# 将所有数值转化成绝对值再求最小值
s_num = min(-5, 1, 2, 3, key=abs) # 1
# key 参数
dic = {'k1': 1, 'k2': 2, 'k3': 3}
def fn(k):
return dic[k]
min_k = min(dic, key=fn) # k1
# 匿名函数写法
min_k2 = min(dic, key=lambda k: dic[k]) # k1
- max(xxx, key=fn) -> 求最大值 -> key = 函数名/匿名函数 -> 如果有 key 那么就会通过 key 的函数返回值进行比较
b_num = max(-5, 1, 2, 3) # 3
b_num2 = max([-5, 1, 2, 3]) # 3
# 将所有数值转化成绝对值再求最大值
b_num = max(-5, 1, 2, 3, key=abs) # -5
# key 参数
dic = {'k1': 1, 'k2': 2, 'k3': 3}
def fn(k):
return dic[k]
max_k = max(dic, key=fn) # k3
# 匿名函数写法
max_k2 = max(dic, key=lambda k: dic[k]) # k3
3. 序列的相关操作
- reversed() -> 列表反转,保留原列表 -> 返回迭代器(返回迭代器是因为不会在内存中有创建多一个列表,节省了内存空间)
# reversed() -> 列表反转,保留原列表 -> 返回迭代器
lis = [1, 3, 2, 5, 4]
r_lis = reversed(lis) # <list_reverseiterator object at 0x0000025B2D023630>
for i in r_lis:
print(i)
# .reverse() -> 直接修改原列表
lis = [1, 3, 2, 5, 4]
lis.reverse()
print(lis) # [4, 5, 2, 3, 1]
- slice() -> 创建切片规则
lis = 'ABCDEFG'
s_rule = slice(1, 5, 2)
s_lis = lis[s_rule] # BD
# 等同于
s_lis = lis[1:5:2] # BD
4. 字符串的相关操作
- bytes('字符串', encoding='编码方式') -> 转码 返回bytes类型 -> 等同于 '字符串'.encode('编码方式')
s = '字符串'
b_str = bytes(s, encoding='utf-8') # b'\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2'
# 等同于
b_str2 = s.encode('utf-8') # b'\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2'
- str('字符串', encoding='编码方式') -> 解码 返回字符串类型 -> 等同于 bytes类型.encode('编码方式')
s = '字符串'
b_str = bytes(s, encoding='utf-8')
s_str = str(b_str, encoding='utf-8') # 字符串
# 等同于
s_str2 = b_str.decode('utf-8') # 字符串
- repr(obj) -> 转化为供解释器读取的形式 -> 用于 %r 格式化输出
s = 'repr'
print(repr(s)) # 'repr' 使用了 repr方法 字符串打印出来会带引号
# 使用 %r
s1 = '引号'
s2 = '带 %r' % (s1) # 带 '引号'
- format() -> 格式化显示 -> http://www.cnblogs.com/Eva-J/articles/7266245.html
- ord('1个字符') -> 返回 Unicode 的 十进制编码
print(ord('d')) # 100
- chr(Unicode 的 十进制编码) -> 返回对应的字符
print(chr(100)) # d
- ascii('ascii码相关字符') -> 返回你所传入的 ascii码相关字符,如果传入了 ascii码之外的字符 会返回 \u……
print(ascii('a')) # 'a'
print(ascii('中')) # '\u4e2d'
5. 集合的相关操作
- frozenset() -> 将集合改变成不可变的数据类型 -> 只能只读
set1 = {1, 2, 3}
f = frozenset(set1) # frozenset({1, 2, 3})
f2 = frozenset('Kevin') # frozenset({'n', 'K', 'e', 'i', 'v'})
6. 和数据结构相关
- len(xxx) -> 获取长度
s = 'ABCDEF'
s_len = len(s) # 6
- enumerate(arr) -> 枚举 -> 对一个可遍历的数据对象(如列表、元组或字符串),enumerate会将该数据对象组合为一个索引序列,同时列出数据和数据的下标
arr = ['一', '二', '三']
for i in enumerate(arr):
print(i) # (0, '一')
for i, k in enumerate(arr):
print(i, k) # 0 一
- zip(序列1, 序列2, 序列3 ……) -> 依次取每个序列中的每个元素组成元组,然后放进迭代器中返回出去
lis1 = [1, 2, 3, 3]
lis2 = ['a', 'b', 'c']
lis3 = ['A', 'B', 'C']
z_lis = zip(lis1, lis2, lis3) # 返回迭代器
zh_lis = list(z_lis) # [(1, 'a', 'A'), (2, 'b', 'B'), (3, 'c', 'C')]
- filter(函数名/匿名函数, 序列) -> 过滤器 -> 返回值: 迭代器 -> 过滤器和推导式加 if 判断一样的,但是过滤器可以进行比较复杂的判断,且比较节省内存
lis = [1, 2, 3, 4, 5, 6, 7, 8]
def f(n):
return n > 5
n_list = filter(f, lis) # <filter object at 0x00000163560C3748>
print(list(n_list)) # [6, 7, 8]
# 等价于 推导式
n_list2 = [i for i in lis if i > 5] # [6, 7, 8]
# 使用匿名函数的写法
lis = [1, 2, 3, 4, 5, 6, 7, 8]
n_list = filter(lambda n: n > 5, lis)
print(list(n_list)) # <filter object at 0x0000026337773710>
print(list(n_list)) # [6, 7, 8]
- map(函数名/匿名函数, 序列) -> 通过函数的返回值组建新的序列 -> 返回值: 迭代器 -> 过滤器和推导式不加 if 判断一样的,但是map可以进行比较复杂的处理,且比较节省内存
lis = [1, 2, 3]
def f(n):
return n + 1
n_list = map(f, lis) # <map object at 0x0000023110AC3748>
print(list(n_list)) # [2, 3, 4]
# 等价于 推导式
n_list2 = [i + 1 for i in lis] # [2, 3, 4]
# 使用匿名函数的写法
lis = [1, 2, 3]
n_list = map(lambda n: n + 1, lis)
print(list(n_list))
- sorted(序列, key=fn) -> 排序 返回值: 新序列 -> 不改变原序列,生成新序列 占内存 -> key = 函数名/匿名函数 -> 如果有 key 那么就会通过 key 的函数返回值进行排序
# sorted() -> 不改变原序列,返回新序列
lis = [2, 5, 3, 4, 9, 1]
n_lis = sorted(lis) # [1, 2, 3, 4, 5, 9]
# .sort() -> 改变序列
lis = [2, 5, 3, 4, 9, 1]
lis.sort()
print(lis) # [1, 2, 3, 4, 5, 9]
# key 参数
# 通过绝对值排序
lis = [2, 5, -3, 4, -9, 1]
n_lis = sorted(lis, key=abs) # [1, 2, -3, 4, 5, -9]
# 通过字符长度排序
lis = ['1', ' ', '23', '12313123', '444']
n_lis = sorted(lis, key=len) # ['1', '23', '444', ' ', '12313123']
- all() -> 判断序列中元素如果有一个为 False 那么就会返回 False -> 字典会判断 key
lis = [1, 2, '', 4, 0]
print(all(lis)) # False
dic = {0: '13', 'key2': 1}
print(all(dic)) # False
- any() -> 判断序列中元素如果有一个为 True 那么就会返回 True -> 字典会判断 key
lis = [1, 2, '', 4, 0]
print(any(lis)) # True
dic = {0: '13', 'key2': 1}
print(any(dic)) # True
7. 进制转换 -> 平时使用的都是 十进制
- bin() -> 十进制 转 二进制
r_bin = bin(10) # 0b1010
- oct() -> 十进制 转 八进制
r_oct = oct(10) # 0o12
- hex() -> 十进制 转 十六进制
r_hex = hex(10) # 0xa
8. 迭代器/生成器相关
- range(startNum,endNum) -> 创建一个整数列表,一般用在 for 循环中 -> 直接打印是不会返回列表只会返回 range(10, 35)(迭代器) -> 当 startNum 缺省时,默认为 0,即 range(,10) 相当于 range(0,10)-> 每进行一次循环就开始创建一个数字返回给你,不会一开始就将全部数字创建出来,这样可以节省内存
for i in range(0, 4):
print(i)
- iter(可迭代对象) -> 获取迭代器 等同于 .__iter__()
lis = [1, 2, 3]
iterator = iter(lis)
# 等同于
iterator = lis.__iter__()
- next(迭代器) -> 一个一个的取值 等同于 .__next__()
lis = [1, 2, 3]
iterator = iter(lis)
num = next(iterator)
# 等同于
num = iterator.__next__()
9. 文件操作相关
- open() -> 打开文件
f = open('log.txt', encoding='utf-8')
r = f.read()
f.close()
10. 输入输出
- input() -> 输入
- 等待输入
- 将你输入的内容赋值给了前面变量
- input 出来的数据类型全部是 str
name = input('请输入你的名字:')
age = input('请输入你的年龄:')
print(
'我的名字是'+name,
'我的年龄'+age+'岁',
type(name)
)
- print(*args, sep=' ', end='\n', file=None) -> 打印
- sep -> 指定输出多个值之间的分隔符 -> 默认空格
print(1, 2, 3, sep="|") # 1|2|3
- end -> 指定输出的结束符 -> 默认回车
print(1, end='')
print(2, end='')
print(3, end='')
# 123
- file -> 指定输出的在上面文件上 -> 默认输出在 PyCharm 控制台上
f = open('file.txt', 'w', encoding='utf-8')
print('打印到文件上', file=f)
f.close()
11. 模块相关
- import -> 引入模块
import time
12. 查看类或对象所拥有的静态属性和方法
- dir(class/obj)
class Foo:
name = 'Kevin'
def show_name(self):
print(self.name)
f = Foo()
print(dir(f))
print(dir(Foo))
print(dir([]))
13. 帮助 -> 查看该对象拥有的方法并且会有使用说明
- help(obj)
print(help([]))
14. 作用域相关
- globals() -> 返回全局作用域所有方法名
print(globals())
- locals() -> 返回本地作用域所有方法名
def fn():
b = 1
print(locals())
fn()
print(locals())
15. 调用相关
- callable(obj) -> 判断对象是否可以被调用
def fn(): pass
print(callable(fn)) # True
print(callable(print)) # True
print(callable('print')) # False
16. 内存相关
- id() -> 返回内存地址
id('内存地址') # 2552402406984
- hash() -> 返回 hash 值 -> 只有不可变的数据类型才能返回 -> 对于相同可hash数据的hash值在一次程序的执行过程中总是不变的
hash('hash值') # -1424203907913749694
17. 将字符串Python代码转换成真正的Python代码执行
- eval('python 代码') -> 有返回值 -> 不建议使用 只能用在你明确知道你要执行的代码是什么
total = eval('1+2+3+4') # 10
- exec('python 代码') -> 没有返回值 -> 不建议使用 只能用在你明确知道你要执行的代码是什么
total = exec('1+2+3+4') # None
- compile('代码', '' ,'eval/exec') -> 预编译 -> 如果代码过多且需要重复调用的时候可以使用 compile 预编译,那么再 eval/execj就不需要再编译多一次 -> 用什么方式预编译的就用什么方式编译
code = 'for i in range(0,10): print (i)'
c_code = compile(code, '', 'exec')
exec(c_code)
18. 反射
- 以字符串类型的变量名或方法名去操作变量或方法
- hasattr(对象, '变量名/方法名') -> 判断对象是否有该变量/方法
class Reflection:
def __init__(self):
self.age = 22
r = Reflection()
print(hasattr(r, 'age')) # True
- getattr(对象, '变量名/方法名') -> 以字符串类型的变量名或方法名去操作变量或方法
- hasattr() 一般配合着 getattr() 使用
class Reflection:
def __init__(self):
self.age = 22
r = Reflection()
if hasattr(r, 'age'): # 判断对象是否有该属性
a = getattr(r, 'age') # 以字符串类型的属性名去获取对象中的属性值
print(a) # 22
- setattr(对象, '变量名', 值) -> 设置或修改变量 -> 没啥用
class SetEdit(): pass
s = SetEdit()
setattr(s, 'name', 'Kevin') # 设置或需改变量名
print(s.name) # Kevin
- delattr(对象, '变量名') -> 删除一个变量 -> 没啥用
class SetEdit():
def __init__(self):
self.name = 'Kevin'
s = SetEdit()
delattr(s, 'name') # 删除一个变量
print(s.name) # 报错
19. 面向对象
- isinstance(对象, 类) -> 检查一个对象是否是这个类的对象
class A: pass
a = A()
print(isinstance(a, A)) # True
class A: pass
class B(A): pass
b = B()
print(isinstance(b, B)) # True
print(isinstance(b, A)) # True 判断 B 实例化出来的对象是否属于 A 类
- issubclass(子类, 父类) -> 检查一个类是否属于另一个类的子类
class Father: pass
class Child(Father): pass
print(issubclass(Child, Father)) # True
20. 相关练习
- 用 map 来处理字符串列表,把列表中所有人都变成sb,比方alex_sb
name = ['alex', 'wupeiqi', 'yuanhao', 'nezha']
# 使用 map 实现
new_name = map(lambda i: i + '_sb', name) # ['alex_sb', 'wupeiqi_sb', 'yuanhao_sb', 'nezha_sb']
# 使用 推导式 实现
new_name1 = [i + '_sb' for i in name] # ['alex_sb', 'wupeiqi_sb', 'yuanhao_sb', 'nezha_sb']
- 用 filter 函数处理数字列表,将列表中所有的偶数筛选出来
num = [1, 3, 5, 6, 7, 8]
# 使用 map 实现
new_num = filter(lambda i: i % 2 == 0, num)
# 使用 推导式 实现
new_num2 = [i for i in num if i % 2 == 0]
- 分页
- 随意写一个20行以上的文件
- 运行程序,先将内容读到内存中,用列表存储。
- 接收用户输入页码,每页5条,仅输出当页的内容
# 写法一: 直接读取出来 节省内存
def page_content(num):
with open('file.txt', encoding='utf-8') as f:
l = f.readlines()
data_num = 5 # 每页显示多少条数据
page, mod = divmod(len(l), data_num)
page_num = page + 1 if mod else page # 总页数
if 0 < num <= page_num:
if num == page_num and mod != 0: # 如果是最后一页且这一页是由多余数据组成的
for i in range(mod):
# 计算方法一: 页数 * 每页显示多少条数据 - 每页显示多少条数据 = 该页开始循环的下标
print('计算方法一 ' + l[num * data_num - data_num + i].strip())
# 计算方法二: (页数 - 1) * 每页显示多少条数据 = 该页开始循环的下标
print('计算方法二 ' + l[(num - 1) * data_num + i])
else:
for i in range(data_num):
# 计算方法一: 页数 * 每页显示多少条数据 - 每页显示多少条数据 = 该页开始循环的下标
print('计算方法一 ' + l[num * data_num - data_num + i].strip())
# 计算方法二: (页数 - 1) * 每页显示多少条数据 = 该页开始循环的下标
print('计算方法二 ' + l[(num - 1) * data_num + i])
else:
print('输入的页数有误')
page_content(3)
# 写法二: 切片 在内存又存储了多一个列表
def page_content(num):
with open('file.txt', encoding='utf-8') as f:
l = f.readlines()
data_num = 5 # 每页显示多少条数据
page, mod = divmod(len(l), data_num)
page_num = page + 1 if mod else page # 总页数
if num > 0 and num <= page_num:
index_start = num * data_num - data_num # 获取切片的开始位置
index_end = index_start + 5 # 获取切片的结束位置
page_list = l[index_start:index_end]
for i in page_list:
print(i.strip())
else:
print('输入的页数有误')
page_content(5)
- 每个小字典的name对应股票名字,shares对应多少股,price对应股票的价格
portfolio = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
# 1. 计算购买每支股票的总价
# 使用 map 实现
price_list = map(lambda j: {j['name']: j['shares'] * j['price']}, portfolio)
print(list(price_list))
# 使用 推导式 实现
price_list2 = [{j['name']: j['shares'] * j['price']} for j in portfolio]
print(price_list2)
# 2.用filter过滤出,单价大于100的股票有哪些
# 使用 map 实现
exceed_price = filter(lambda j: j['price'] > 100, portfolio)
print(list(exceed_price))
# 使用 推导式 实现
exceed_price2 = [j for j in portfolio if j['price'] > 100]
print(exceed_price2)